- E-mail hello@ancelus.com
- Phone (317) 559-3529
About ancelusDB
Time Compression Strategies (TCS) has developed the gold standard for graph database technology. Based in Indianapolis, Indiana, the majority of TCS stockholders and one-third of our board are women. Today, we are a women-owned business, and continue the legacy of high efficiency and extremely reliable software. For decades, our streaming analytics systems set records for performance and profitability. Our products are installed on over 30,000 systems worldwide.
TCS started the quest for extreme database performance because we were unable to find tools to support our application development vision. The Ancelus design team first developed and delivered real-time systems in 1983. In 1986, the design team produced its first in-memory database, operating in a 16-bit environment. A second generation 32-bit version was patented in 1993, with Ancelus database patents being secured in 2010 and 2011. In 2013, the third generation of our Ancelus design, ancelusDB, was created as the first patented, hybrid, algorithmic, graph database.
What is ancelusDB?
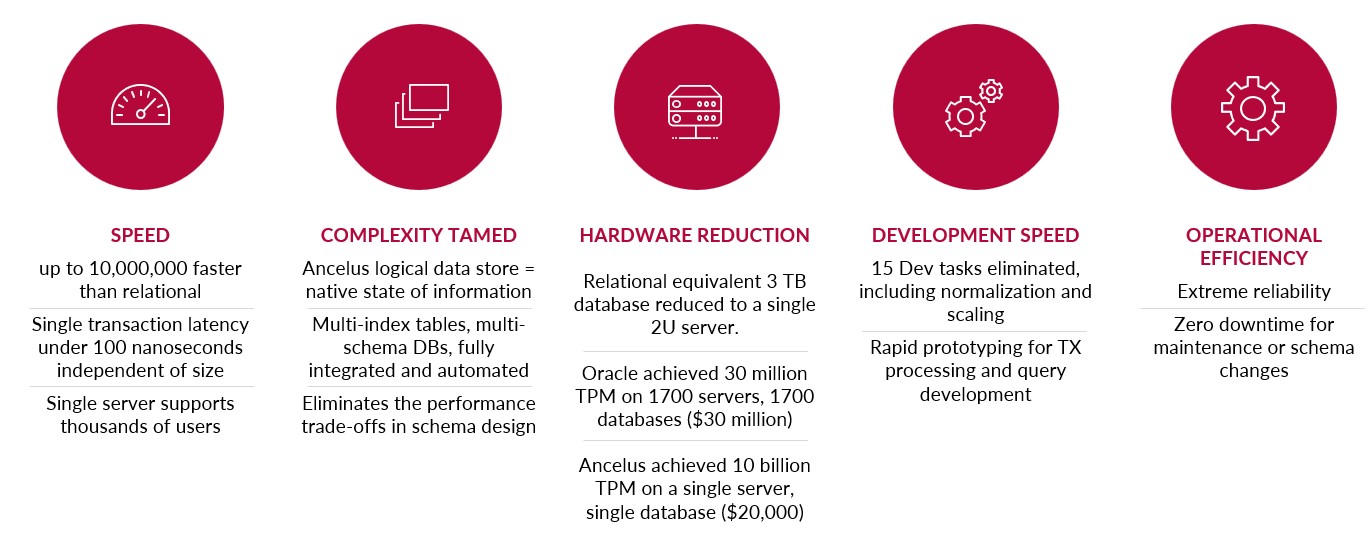
ancelusDB outperforms in the areas of reliability, zero maintenance downtime, real-time revisions, scalability, and agility. Our product is the first ACID compliant database to deliver extreme speed with ultimate complexity handling on a massive scale in a single system.
Becoming known as the “database that never sleeps,” ancelusDB deployments are expected to save operational costs through continuous high processing speed on smaller servers. All maintenance, admin and schema revision functions execute while the database is live. Data can be “pipelined” into and out of the database without downtime. Re-indexing occurs on every transaction and is included in the benchmark measures.
What Makes ancelusDB Work?
“The Ancelus database uses a patented algorithmic approach to data storage that replaces predefined storage structures with an algorithm that determines the physical storage location of data.” (“Data and Technology Review of Ancelus DB – Ancelus”) This algorithmic approach decides where to put data based on access efficiency so that physical data storage and retrieval are independent of any predefined data layout.
ancelusDB couples this storage approach with in-memory data access techniques which are also based on patented memory management methods. By combining algorithmic data storage and in-memory data management, Ancelus achieves constant nanosecond performance even for very large databases and complex applications.
There is no duplication of data in an Ancelus database. Each data element is stored only once, and data is linked using pointers to its data dictionary. A consequence of this design is that referential integrity is not optional—it is designed right into the database … and it does not impede performance.
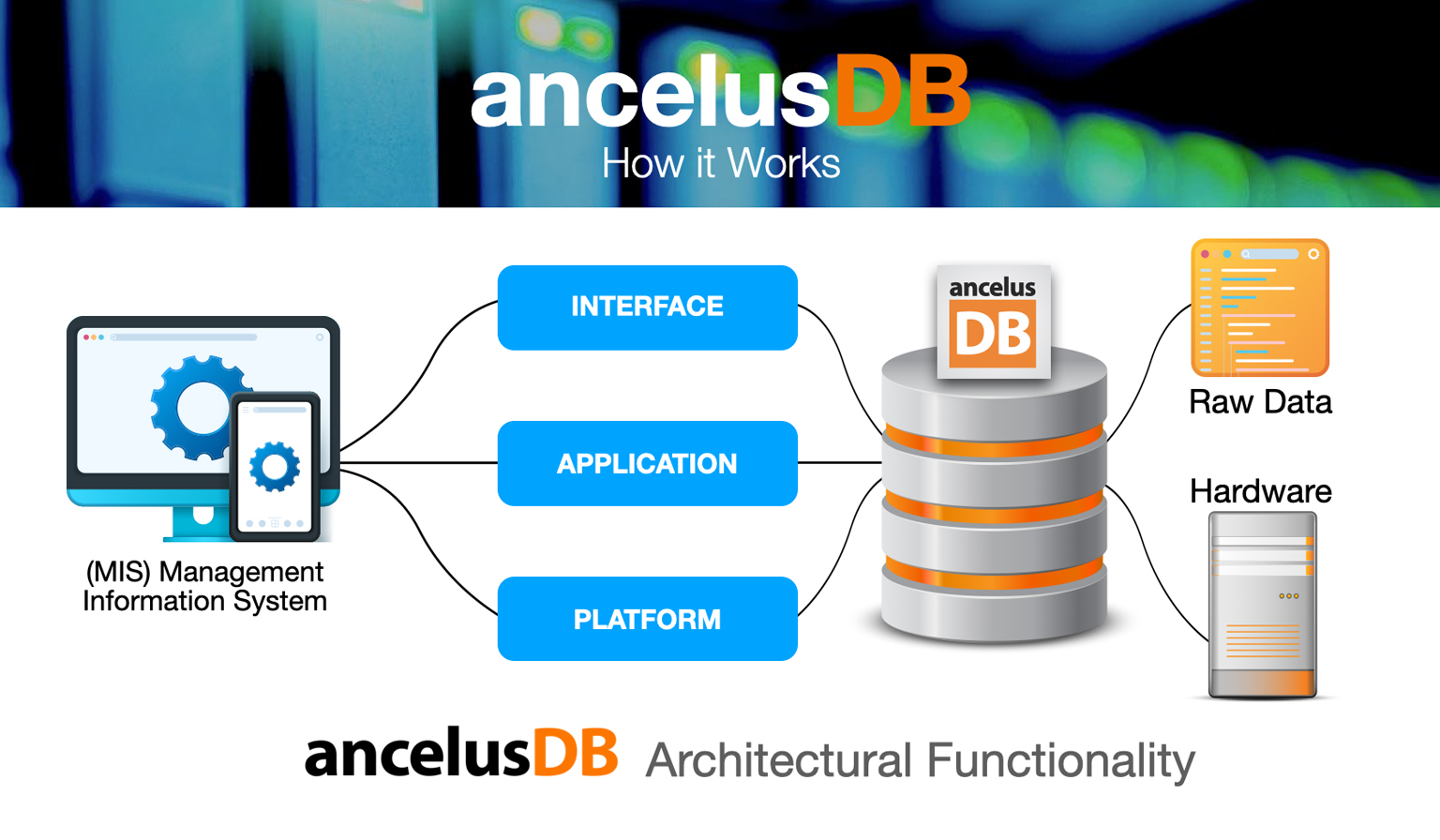
With this architecture, users can implement multiple logical schemas over the data at the same time, to access the data as it is in relational tables (even though it is not). The actual physical schema is not exposed to users.
ancelusDB can be run on Linux, UNIX, and Windows platforms.
What Makes ancelusDB Different?
- ancelusDB is leading the movement to transition to algorithmic database methods and away from structured data storage.
- Cost to keep up with technology – can save millions on hardware by buying the right software
- ancelusDB is 10,000 times faster than the self-proclaimed “fastest”and 80% cheaper.
- Some of the tools and processes you would normally use in today’s databases you don’t do in ancelusDB. We use Ancelus compression which reduces the number of servers, electricity, and hardware costs by as much as 70%.
- ancelusDB works efficiently for both transactions and analytics, supporting HTAP (Hybrid Transaction Analytical Processing) and translytical environments. ancelusDB is not a SQL database system; data is typically accessed by a native API. However, ancelusDB does offer TQL (Threaded Query Language), which converts ancelusDB schema structures into SQL-readable formats for ease of integration.
- ancelusDB protects against many of the development problems that consume developers’ time. ancelusDB can automate or eliminate 15 development tasks from the typical software project. Find Your Hardest Problem and Skip it!!
Tasks Ancelus Developers DON’T DO:
- No table design step (optional)
- No add-on data marts, secondary schemas, master data management
- No normalization debate, 100% normalized + 100% de-normalized at the same time
- No “where-used” search
- No data duplication for foreign keys or concatenated keys
- No insert vs. retrieval performance trade. Eliminates “no-schema” patch
- No column compression to reduce scarcity
- No downtime for garbage collection
- No downtime for maintenance
- No downtime for re-indexing
- No downtime to re-balance the binary tree
- No downtime for schema changes
- No downtime for re-sharding
- No downtime for re-defining or reloading hypercubes
- No downtime for distributed data re-synchronization